The great thing about the Panda’s library for Python is how easily it can manipulate data sources. We will look at one of the first things you will want to do, read a .csv file.
Read .csv file using a Panda Dataframe
|
1 2 3 |
import pandas buyclicksDF = pandas.read_csv("buy-clicks.csv") buyclicksDF.shape |
First we need to import the pandas library.
Next we will store the .csv file into a local variable called buyclicksDF.Lastly we will use the shape command to display the number of rows and columns. The results are 2947 rows and 7 columns
|
1 |
(2947, 7) |
Now let’s take a look at some sample rows and see what they look like.
|
1 |
buyclicksDF.head(7) |
And the results we get are as follows.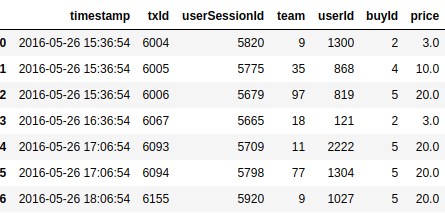
Now we will read another file into a data frame and again look at the first seven rows.
|
1 2 |
adclicksDF = pandas.read_csv("ad-clicks.csv") adclicksDF.head(7) |
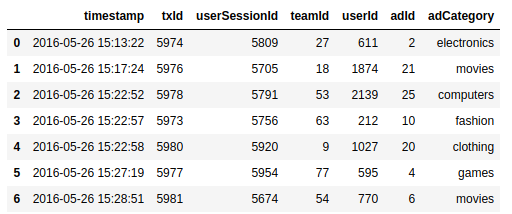
Joining Dataframes
Now that both dataframes are loaded we will want to join them together, and then take a look at the first seven rows.
|
1 2 |
mergeDF = adclicksDF.merge(buyclicksDF, on = "userId") mergeDF.head(7) |
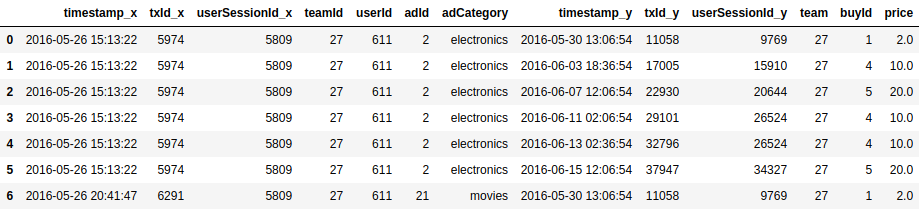
Joining the dataframes you specify the method .merge from one dataframe and specify what columns to use to join them on. In this simple case both dataframes have a column labeled userId and we will join on that column. And finally we stored the results into a new dataframe labeled mergeDF.
I hope you found the above informative, let me know if you have any questions in the comments below.
— michael.data@eipsoftware.com
Leave a Reply