Spark – SQLContext
Today we will look at the SQLContext object from the PySpark library and how you can use it to connect to a local database. In the example below we will:
Connect to a local PostgreSQL database and read the contents into a dataframe.
Run some simple SQL queries
And join two data frames together
Let’s get started.
Initializing Environment
In the environment I was using I had a local instance of a PostgreSQL database installed.
I had a database called “Cloudera”. You can see all available databases in PostgreSQL by using the \list command from a PostgreSQL prompt. There are 3 tables in the database, adclicks, buyclicks, and gameclicks. Use the \dt command to show the tables in the database.
Python Code
First we need to import the object from the PySpark library. And will create an object of type SQLContext named sqlsc.
|
1 2 |
from pyspark.sql import SQLContext sqlsc = SQLContext(sc) |
Next will read the contents of the gameclicks table and store the result into a dataframe named df. And then we can see the results of the schema. I am using jdbc:postgresql driver to connect to the database.
|
1 2 3 4 5 6 |
df = sqlsc.read.format("jdbc") \ .option("url", "jdbc:postgresql://localhost/cloudera?user=cloudera") \ .option("dbtable", "gameclicks") \ .load() df.printSchema() |
The gameclicks schema is below.

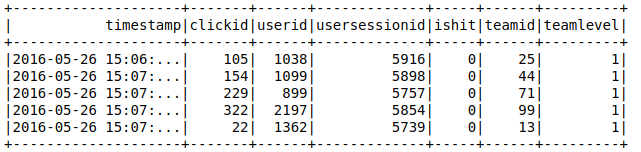
Now, we will count how many rows are in the data frame and show the top 5 rows.
|
1 2 3 |
df.count() df.show(5) |
|
1 |
755806 |
PySpark Queries
Now that the data frame is loaded we can perform some simple queries.
First we will do a query that only brings back specified columns and first five rows. And you can see the results below.
|
1 |
df.select("userid", "teamlevel").show(5) |

Next we can use the filter method on the data frame, similar to the WHERE clause in a traditional SQL query.
|
1 |
df.filter(df["teamlevel"] > 1).select("userid" ,"teamlevel").show(5) |

Aggregation Queries
Now we will do some simple aggregation queries.
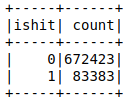
Now let’s group the results by the value in the IsHit column.
|
1 |
df.groupBy("IsHit").count().show() |
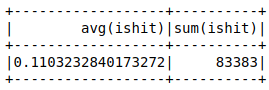
If we want to do additional types of aggregations beyond counting we will need to import the SQL functions from the PySpark library. And then we will take the mean and the sum of the IsHit column.
|
1 2 |
from pyspark.sql.functions import * df.select(mean("IsHit"), sum("IsHit")).show() |
Joining Tables
The last task for this post is to show how to join tables.
We will read the adclicks table into a dataframe and join it to the game clicks table. We will join on the userid column.
Similar to above we will use the jdbc driver to load the dataframe and store it in a data frame object.
|
1 2 3 4 5 6 |
df2 = sqlsc.read.format("jdbc") \ .option("url", "jdbc:postgresql://localhost/cloudera?user=cloudera") \ .option("dbtable", "adclicks") \ .load() df2.printSchema() |
Here are the schema results

Now we can use the .join method similar to an inner join in an SQL query and join the two data frames.
|
1 2 3 |
dfMerge = df.join(df2, "userid") dfMerge.printSchema() |
The merged schema

|
1 |
dfMerge.show(7) |
And now we can take a look at what the merged data frames look like.

In this post we did quite a few things. Looked at loading tables from a PostgreSQL database, performing some simple SQL queries on the data frames, and joined the data frames together.
I hope you found the above informative, let me know if you have any questions in the comments below.
— michael.data@eipsoftware.com
Leave a Reply